分布式系统设计模式
Categories:
本文是对 Nishant 文章 Distributed System Design Patterns 的翻译,主要介绍分布式系统相关设计问题中涉及到的关键模式。
Keys
1.布隆过滤器
布隆过滤器是一个空间友好的概率数据结构,通常用来判断数据是否是集合中的一个元素,其通常用于我们需要知道某个元素是否属于某类对象的场景。具体应用见下图:
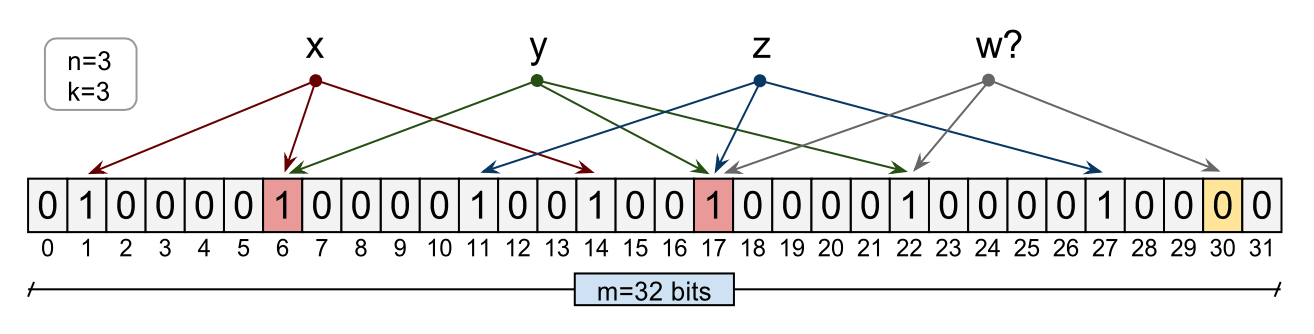
在BigTable,一个分布式数据存储系统中,任何读操作都需要读取构成 Tablet 的所有 SSTables 结构。当 SSTables 结构不在内存的时候,需要进行大量的磁盘 io 才能完成一个读请求,为了减少磁盘读写次数,BigTable 使用了布隆过滤器。
2.一致性哈希
一致性哈希可以帮助开发者更加容易有效的扩展和复制数据,并且保证良好的可用性和容错能力。
每个被key标识的数据项最终都会分配到一个节点,具体计算逻辑是,通过对数据项的key值进行 hash 可以计算出该key值在环上的位置,然后沿着哈希环顺时针行走,直到发现第一个比key值的位置大的节点,发现的这个节点就是将要分配给key标识的数据项的节点。示例:
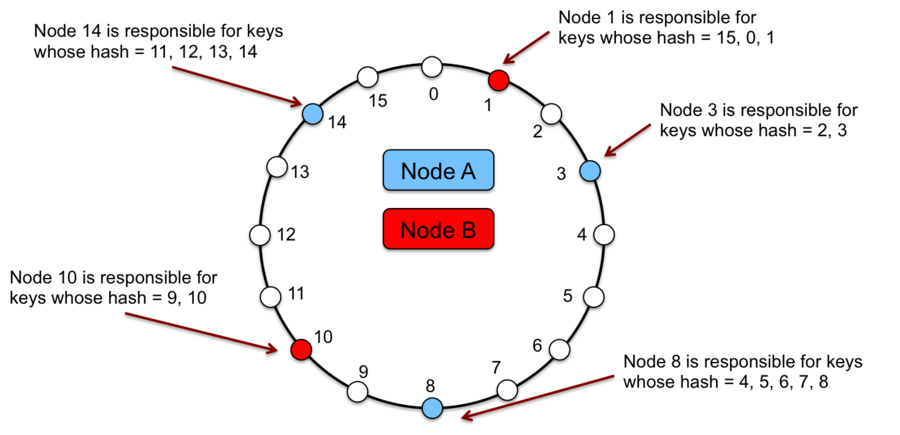
一致性 hash 的主要优势是增量稳定性,集群中的节点删除和新增仅仅影响其相邻的节点,其他的节点不受影响。
3.Quorum
在分布式环境中,quorum指的是所有的分布式操作执行成功所需要的最小服务数目。
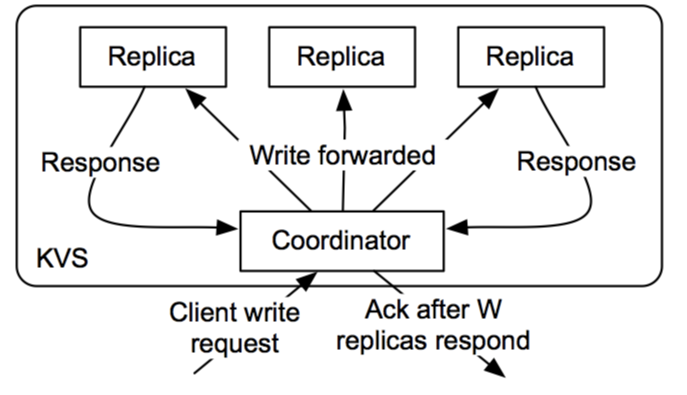
Cassanddra(一个开源分布式 NoSQL 数据库系统),为了确保数据一致性,可以配置对于每一个写请求只有当数据写入副本节点中至少一个quorum才算成功。
对于 Leader 选举,Chubby 使用Paxos,它使用quorum来保证强一致性。Raft 和 Paxos 共识算法学习参考资料:Raft user study。
Dynamo复制写入数据到整个系统其他节点的一个 quorum 中,而不是像 Paxos 一样严格的大多数 quorum 中。系统的所有的读写操作都会被 preference list 上的第一个正常的节点执行,该节点不一定总是在遍历一致性哈希环是遇到的第一个节点。
4.Leader and Follower
为了确保数据管理系统的容错性,需要在集群内的多个服务器上复制数据。所以需要在该集群内选出一个服务作为leader, leader负责代表整个集群做出决策,并将决策传播到剩余的其他服务器,其他机器可以看作是follower。
…
5.心跳
心跳机制用于检测现有的 leader 服务状态,如果不正常的话需要开始新的 leader 选举。
6.Fencing
在上面 leader-follower 模型中,当一个 leader 失败之后, 我们无法确定该 leader 是否已经停止工作。比如说,受网络环境或者网络分区的影响,可能会触发新的 leader 选举,然而此时先前的 leader 仍旧在作为一个活跃的 leader 正常工作。
Fencing是解决上面这种问题的一个解决方案。Fencing会在先前的 leader 周围设置一个屏障,这样该 leader 就无法正常访问集群资源,从而停止处理所有的读写请求。
具体实现时有以下两种实现思路:
- 资源屏障:系统阻止以前活跃的 leader 访问执行基本任务所需的资源。
- 节点屏障:系统阻止之前活跃的 leader 访问所有资源, 执行此操作的常用方法是关闭或重置节点。
7.预写日志
8.Segmented Log
9.High-Water mark
10.Lease
11.Gossip Protocol
12.Phi Accrual Failure Detection
13.Split-brain
14. Checksum
15.CAP Theorem
CAP 定理指出,分布式系统不可能同时具有以下三个属性:
- 一致性,Consistency (C)
- 可用性,Availability (A)
- 分区容错性,Partition Tolerance(P)
根据 CAP 定理,任何分布式系统都需要满足三个属性中的两个。这三个选项是 CA、CP 和 AP。
Dynamo:该分布式系统属于 CAP 理论模型中的 AP 系统,旨在以牺牲强一致性为代价实现高可用性。
BigTable:该分布式系统属于 CAP 理论模型中的 CP 系统,它具有严格一致的读取和写入。
16.PACELEC Theorem
PACELEC 定理指出,在复制数据的分布式系统中,
- 如果分布式系统存在网络分区(P)的情况下,必须在可用性(A)和一致性(C)之间进行选择(和 CAP 定理相同)
- 否则(E),即使系统在没有分区的情况下正常运行,也必须在延迟(L)和一致性(C)之间进行选择
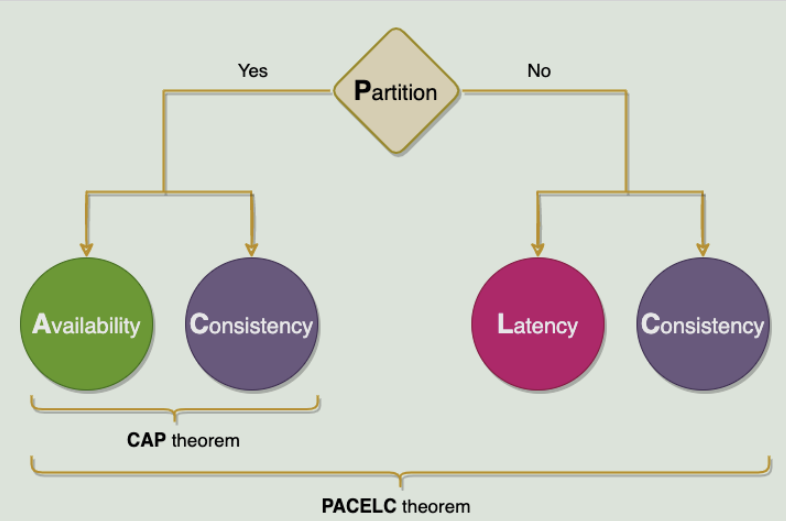
定理(PAC)的第一部分与 CAP 定理相同,ELC 是扩展。整个论点假设我们通过复制来保持高可用性。因此,当系统出现故障时,选择 CAP 定理。但如果没有,我们仍然需要在复制系统的一致性和延迟之间做出选择。